Sokszor dolgozunk Solr-ral a projektjeinken, gyakran jönnek elő kisebb-nagyobb hibák, fejlesztési kérések.
A Solr egy nyúlüreg, amiben nagyon mélyre lehet menni, de már néhány egyszerűbb ismeret is elég ahhoz, hogy az ilyen jellegű kérdéseket viszonylag rövid időn belül meg tudjuk válaszolni:
“A tartalom x mezőjében szerepel ez a szó: xyz, de ha a keresőbe beírom, mégsem kapok találatot. Miért?”
Integral Vision
Az alábbiakban két esetet mutatok be részletesen – a tanulság mindkettőnél más, és jól illusztrálja, hogy ugyanaz a tünet milyen különböző okokra vezethető vissza.
Első eset.
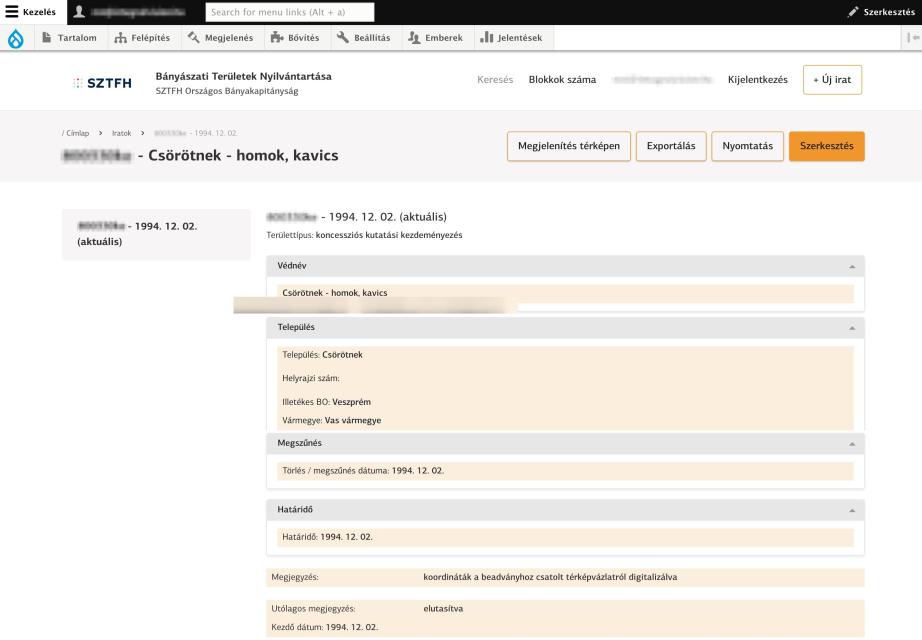
“A megjegyzés mezőben való keresésnél nem listáz ki minden eredményt. Azt vettem észre, hogy ahol nem csak a Megjegyzés, hanem az Utólagos megjegyzés mező is ki van töltve azok nem jelennek meg a keresés eredményeként. Pl.: ha beírom, hogy <<digitalizálva>>, akkor 3 találatot kapok a 4 helyett, nem listázza a <<Csörötnek - homok, kavics>> című tartalmat, pedig a megjegyzésben szerepel:”
Két irányból lehet elindulni: a kód vagy a Solr felől. Lássuk az utóbbit.
Az első kérdés, amit ilyenkor felteszek magamban: egyáltalán szerepel-e olyan címmel dokumentum a Solr indexemben, amit az ügyfél találatként látni kíván?
A Solr az alapértelmezett beállítás szerint a http://localhost:8983/solr/ URL-en érhető el. Ha megnyitom a felületet, a bal oldalon a menüben a Query menüpontra kattintok.
Tudjuk az ügyféltől, hogy melyik tartalom hiányzik a találataink közül, ismerjük a címét: “Csörötnek - homok, kavics”
Ha nem tudom fejből, hogy a cím mezőt a Solr mire képezi le magának, akkor az egyszerűség kedvéért megnézek egy tetszőleges találatot, és abból kilesem a címet tartalmazó mező nevét. Ehhez csak annyit csinálok, hogy letekerek az űrlap aljára, és rányomok az Execute Query gombra.
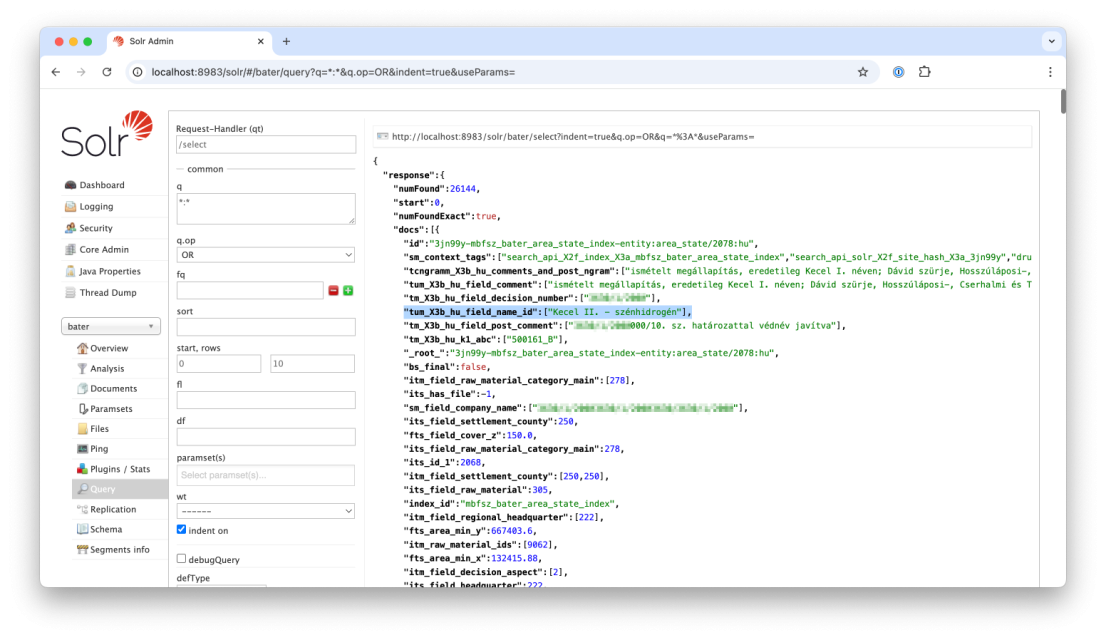
A numFound jelzi a találatok számát. Mivel nem szűkítettem a listát semmilyen feltétellel, ez most azt mutatja, hány dokumentum található összesen az indexemben.
Az első dokumentumot alaposabban megnézem, megtalálom benne a címet tartalmazó mezőmet: tum_X3b_hu_field_name_id
A megjegyzés mezőt is látom: tm_X3b_hu_comments_and_post_ngram
Most rákeresek arra a karaktersorozatra, amire az ügyfél: tm_X3b_hu_comments_and_post_ngram:”digitalizálva”
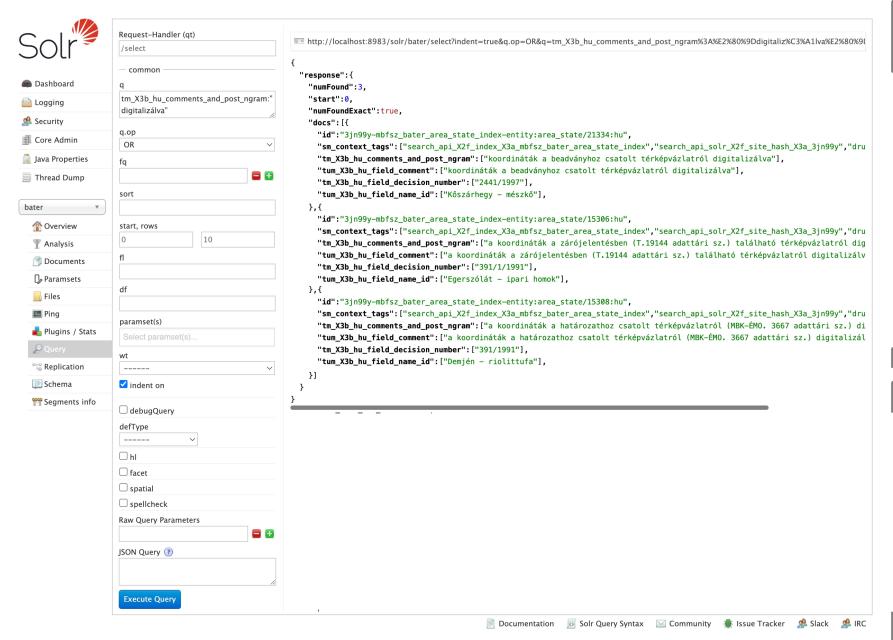
Valóban csak 3 találatot ad, és nincs köztük Csörötnek. Akkor lássuk a hiányzó tartalmat, megjelenik-e egyáltalán a Solr-ban!
Most a címre keresek, ehhez a ‘q’ mezőben a *:*-ot átírom erre:
tum_X3b_hu_field_name_id:"Csörötnek - homok, kavics"
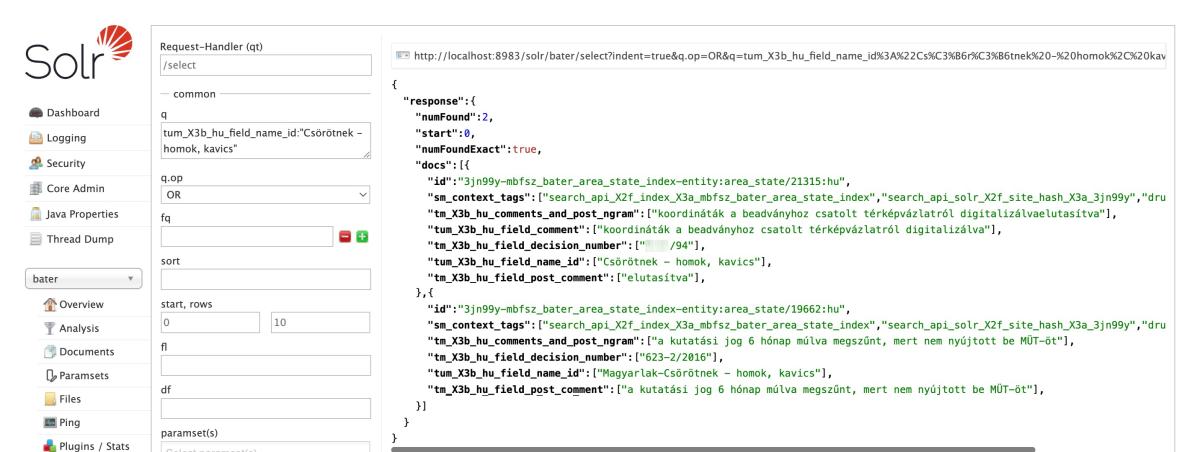
Van találatom! Ebből megtudtuk, hogy a Solr beindexelte ezt a tartalmat, ez már fél siker. És most megnézem a megjegyzés mezőt, hogyan képezte le magának a Solr:
"tm_X3b_hu_comments_and_post_ngram":["koordináták a beadványhoz csatolt térképvázlatról digitalizálvaelutasítva"],
Látszik is a probléma: a két mező úgy lett összefűzve az indexelés során, hogy nem tettünk közéjük szóközt. Ha erre keresek rá: “digitalizálvaelutasítva”, megkapom találatként Csörötneket:
Tehát csak annyi a teendő, hogy a kódban megkeresem azt a részt, ami a megjegyzés mezők összefűzéséért felel:
$comment = $change->get('field_comment')->getString();
$comment_post = $change->get('field_post_comment')->getString();
return $comment . $comment_post;
Beteszem a hiányzó szóközt, újraindexelem a tartalmakat, és voilá, Csörötnek feltűnik a találatok között.
Második eset.
“Ha a címben rákeresek arra, hogy “Hatvan” nem ad találatot, pedig van sok ilyen című tartalom: Hatvan - szénhidrogén”
Lássuk ismét a fenti lépéseket: szerepel-e Hatvan - szénhidrogén címmel tartalom a Solr indexemben?
Most már ismerem a cím mezőt, a ‘q’ mezőben a *:*-ot átírom erre:
tum_X3b_hu_field_name_id:"Hatvan - szénhidrogén"
Van találatom. Nem is kevés, 5023 db. Ha viszont azt írom be, amit az ügyfél:
tum_X3b_hu_field_name_id:"Hatvan”
akkor nincs találat. Rejtély.
A Query felülettel eddig nem jutottunk közelebb a megoldáshoz – a tartalom ott van az indexben, mégis láthatatlan. Ilyenkor jön jól az Analysis menüpont, amely megmutatja, hogyan dolgozza fel a Solr az indexelt szöveget és a keresőkifejezést, és hogy a kettő között van-e egyáltalán metszet.
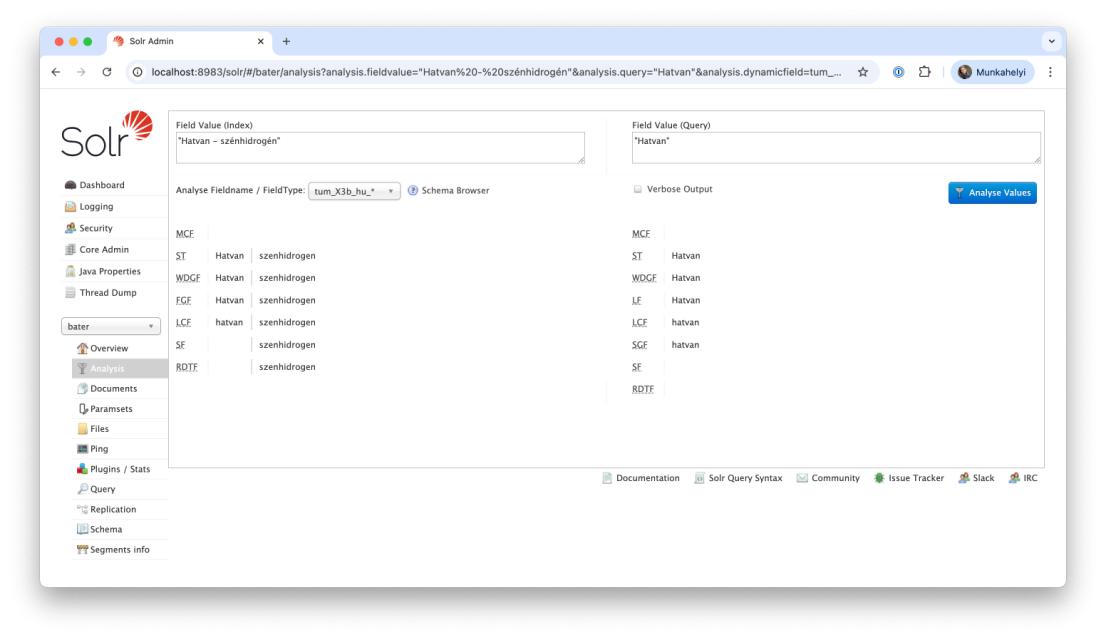
Két oszlopot látunk: a bal oldalra tudom beírni azt, hogy milyen adat szerepel az indexemben, a jobb oldalra azt, amire keresek, a Solr pedig megmutatja, hogyan dolgozza fel ezeket lépésről lépésre. Levezeti nekem, mi zajlik ilyenkor a háttérben, miért van vagy épp nincs egyezés.
Mi is van az indexemben? "Hatvan - szénhidrogén" Mi a mezőm típusa? Kikeresem a megfelelő prefixet: tum_X3b_hu_* És mire kerestem a keresőben? “Hatvan” Na lássuk!
A bal oldalon azt látom, hogy az indexemben lévő értéket hogyan csupaszítja le a Solr a mező típusától függően.
Sok-sok ismeretlen rövidítést látunk: MCF, ST, WDGF, stb. Ezek olyan eljárások, ún. filterek, amelyeket a Solr a szöveg indexelése és elemzése során alkalmaz.
Amikor nem jut eszembe, melyik filter micsoda, akkor a Solr conf mappájában rákeresek a mezőm típusára: tum_X3b_hu_
A schema_extra_fields.yml fájlban meg is találom ezt a sort:
<dynamicField name="tum_X3b_hu_*" type="text_unstemmed_hu" stored="true" indexed="true"
multiValued="true" termVectors="true" omitNorms="false" />
Ebből megtudom a mezőm típusát: text_unstemmed_hu
A schema_extra_types.xml fájlban erre keresve megtalálom a különös rövidítések magyarázatát:
<fieldType name="text_unstemmed_hu" class="solr.TextField" positionIncrementGap="100" storeOffsetsWithPositions="true">
<analyzer type="index">
<charFilter class="solr.MappingCharFilterFactory" mapping="accents_hu.txt"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="0" generateNumberParts="0"
protected="protwords_hu.txt" splitOnCaseChange="1" generateWordParts="1" preserveOriginal="1" catenateAll="0"
catenateWords="0"/>
<filter class="solr.FlattenGraphFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords_hu.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<charFilter class="solr.MappingCharFilterFactory" mapping="accents_hu.txt"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="0" generateNumberParts="0"
protected="protwords_hu.txt" splitOnCaseChange="0" generateWordParts="1" preserveOriginal="1" catenateAll="0"
catenateWords="0"/>
<filter class="solr.LengthFilterFactory" min="2" max="100"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SynonymGraphFilterFactory" ignoreCase="true" synonyms="synonyms_hu.txt" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords_hu.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
A filterek valóban megegyeznek azzal, amit az analyzer mutat:
MCF - MappingCharFilterFactory
ST - StandardTokenizerFactory
WDGF - WordDelimiterGraphFilterFactory
FGF - FlattenGraphFilter
LCF - LowerCaseFilterFactory
SF - StopFilterFactory
RDTF - RemoveDuplicatesTokenFilterFactory
Látható az is, milyen egyéb konfigurációs fájlokat használ a Solr az egyes filterekhez - például a WordDelimiterGraphFilter-hez a protwords_hu.txt-t, StopFilter esetén a stopwords_hu.txt-t.
Hogy dolgozza fel tehát a Solr a “Hatvan - szénhidrogén” karaktersorozatunkat?
Az MCF a MappingCharFilter, ami első lépésben az ékezeteket tünteti el.
Az ST a Standard Tokenizer, ami szavakra bontja a szövegemet. A “Hatvan - szénhidrogén”-ből így lesz a második lépés után “Hatvan” és “szenhidrogen”.
A WDGF, vagyis a WordDelimiterGraphFilter, a szavakat tovább bontja elválasztó karakterek mentén (pl. "wi-fi" → "wi", "fi”).
Az FGF, vagyis a FlattenGraphFilter teszi lehetővé, hogy miután a wi-fi ketté lesz bontva wi és fi-re, utána egyben is szerepeljen az indexben: “wifi”-ként. Esetünkben ennek nincs jelentősége.
Az LCF a LowerCaseFilter, kisbetűssé alakítja a szavakat.
Az SF a StopFilter, ami eltávolítja az olyan gyakori, de a keresés szempontjából gyakran irreleváns szavakat, mint például a névelők, névmások, kötőszavak, stb.
És hopp, meg is van a gond! A StopFilter alkalmazása után eltűnt a “hatvan”. A StopFilter, ahogy azt a schema_extra_types.xml fájlból megtudtuk, egy stopwords_hu.txt fájlból dolgozik. Ennek aktuális állapotát meg tudom nézni a Files menüpontra kattintva is. Itt látom, hogy a stopwords bizony az összes számnevet is tartalmazza.
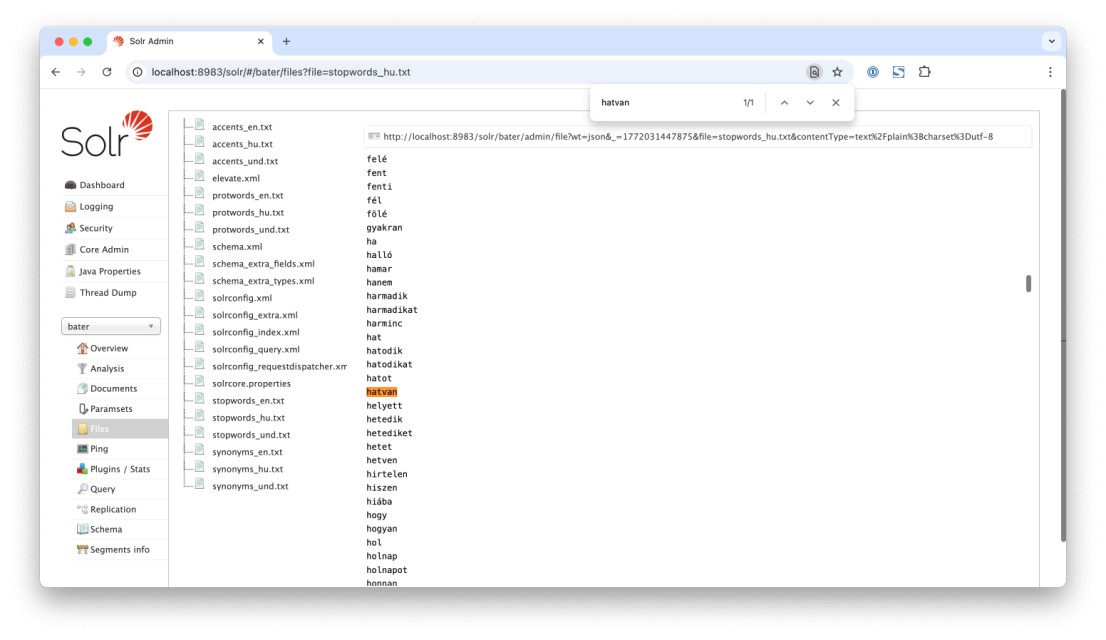
Mi a megoldás? Kivesszük a stopwords-ből a hatvanat. (A Solr conf mappájának helyét az Overview menüpont segít megtalálni.)
A fájl módosítása után újra be kell töltenünk a frissített konfigurációs fájlokat, amit a Core Admin menüpontban a Reload gombra kattintva tehetünk meg.
Ha ezután újra lefuttatjuk az analízist, a kiemelés azonnal mutatja, hogy már van találat, és az is látható, hogy az SF nem tüntette el a keresett szót. Éljen!
Már csak annyi maradt hátra, hogy újraindexeljük a tartalmakat, és lám, Hatvan megjelenik a felhasználók számára is.
Ha már itt tartunk, álljon itt egy rövid lista azokról a magyar helységnevekről, melyek alapértelmezetten stopwords-ként vannak titulálva, mert a Solr keresési szempontból irrelevánsnak ítéli őket. Ha viszont helységnévre is kereshetnek a felhasználók, ezeket érdemes eltávolítani a stopwords fájlból:
- Bár
- Rád
- Velem
- Hatvan
- Hét
- Sé
Problémát okozhatnak továbbá a kétbetűs magyar helységnevek is, ha olyan beállítást alkalmazunk, ahol a kereséshez minimum 3 karakter megadása szükséges:
- Ág
- Bő
- Őr
- Sé
Share with your friends!