
A vasúti és logisztikai szektorban egyre gyakrabban merül fel az igény, hogy más rendszerekből exportált, nagyméretű Excel fájlokat kell üzleti logikával együtt integrálni egy központi rendszerbe. A piacon sok fejlesztés elakad azon a ponton, hogy az importfolyamat túl lassú, nem skálázható, vagy nem nyújt megfelelő hibakezelést. Gyakori a „vaktöltés” – amikor egy hibás fájl megakasztja a teljes folyamatot, és nem derül ki pontosan, mi a hiba forrása.
Az ECMT (Európai Vasúti Kapacitáskezelési Eszköz) projekt során ezek a kihívások nálunk is jelentkeztek. A megoldás kulcsa az volt, hogy saját technológiai eszköztárunkra és fejlesztési keretrendszerünkre támaszkodva gyorsan, skálázhatóan és visszajelzés-központúan tudtuk újragondolni az egész importfolyamatot.
A kiinduló igény: több forrásból származó adatok integrálása
A felhasználói oldalról érkezett igény az volt, hogy más rendszerekből exportált objektumokat is meg lehessen jeleníteni az ECMT rendszerben. A korábbi importfunkció kb. 10.000 soros fájlokat tudott kezelni – ez messze alatta maradt a tényleges szükségletnek.
Hogyan oldottuk meg?
A megoldást saját fejlesztésű, Drupal-alapú platformunkra és Python-alapú kiegészítő komponenseinkre építettük. Ez lehetővé tette, hogy:
- a fájlokat darabokra bontva (chunkolva), párhuzamosan dolgozzuk fel,
- üzleti logikákat már a korai fázisban validáljunk,
- és akár 300.000 soros fájlokat is biztonságosan, gyorsan, strukturált visszajelzéssel kezeljünk.
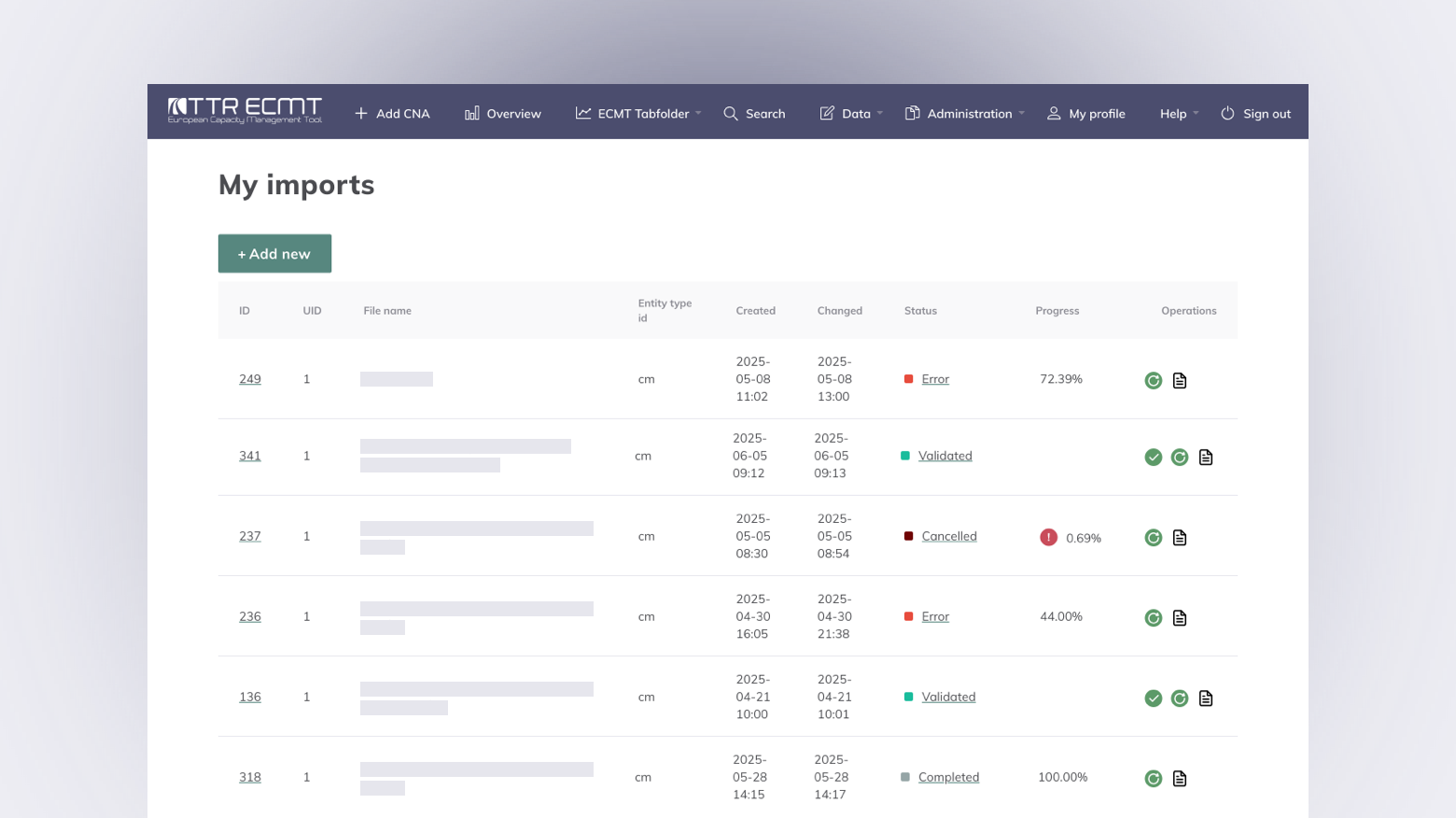
A megoldás fő elemei
Üzleti logika alapú validáció:
Az import nem csak technikai érvényességet ellenőriz, hanem üzleti szabályokat is. Például: jogosultságok ellenőrzése, útvonalak helyessége, dátumkonzisztencia, vonattípus-ütközések elkerülése.
Saját fájlformátum:
Az Excel fájlokat belső, optimalizált formátumba konvertáljuk, így nem kell minden egyes olvasáskor újra feldolgozni az eredetit.
Előellenőrzési fázis:
Már a folyamat elején visszajelzést adunk az alapvető hibákról – például ha a fájl nem felel meg a sablonnak –, így nem terheljük feleslegesen a teljes rendszert.
Chunkolás és párhuzamos feldolgozás:
A fájl kisebb egységekre bontva kerül feldolgozásra. Amennyiben bármelyik rész hibára fut, a teljes folyamat leáll, és a felhasználó pontos hibaüzenetet kap.
Visszajelzés a feldolgozás állapotáról:
Mivel a nagy fájlok importja időigényes folyamat, kiemelten fontosnak tartottuk, hogy a felhasználó folyamatos visszajelzést kapjon arról, épp hol tart a rendszer. A státuszokat színkódokkal jelöltük, a folyamat előrehaladását pedig százalékos értékkel (progress %) is megjelenítettük. Ez átláthatóvá és kiszámíthatóvá teszi a teljes importfolyamatot.
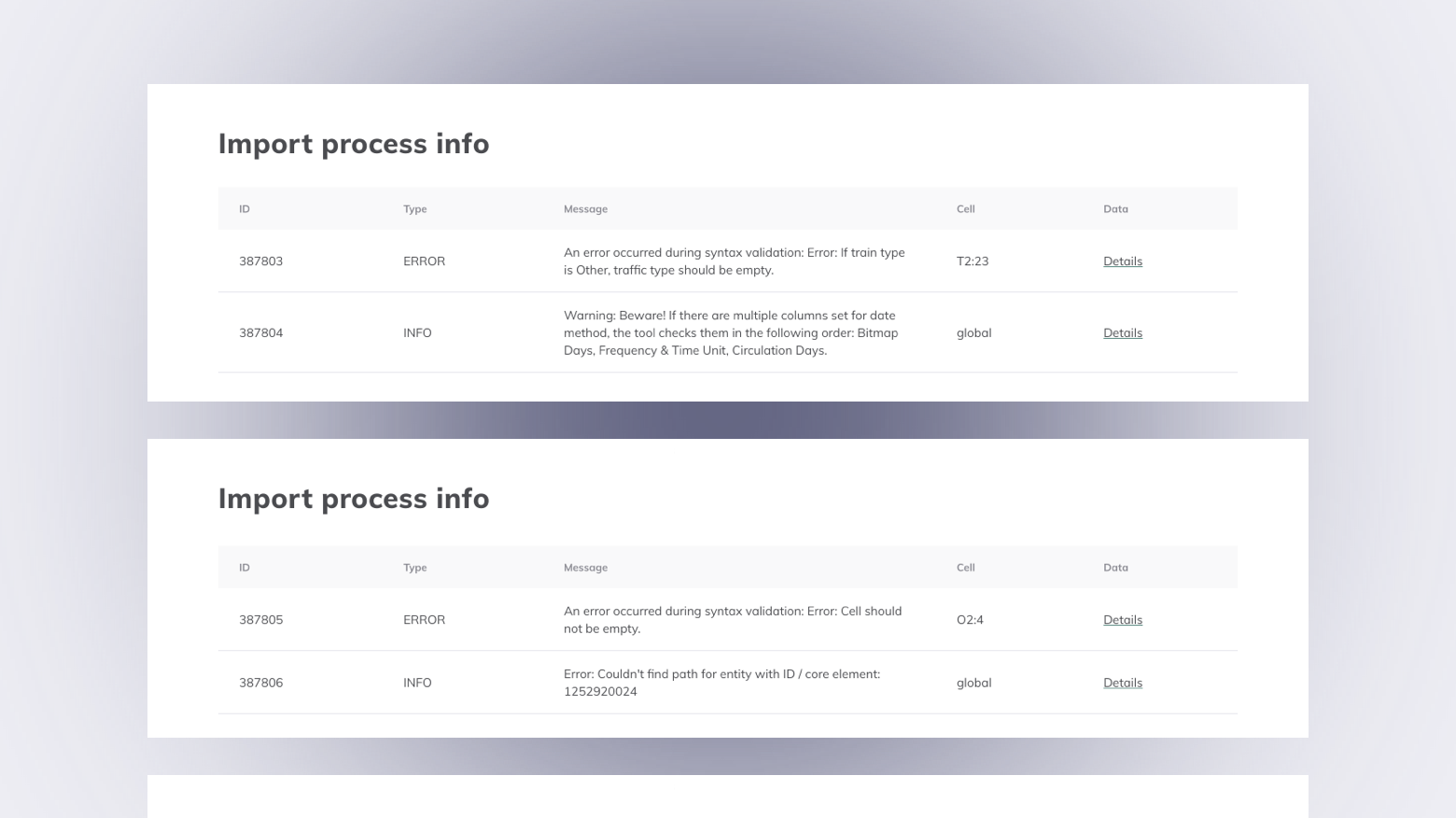
Egységes validációs logika:
A rendszerben már meglévő UI-validátorok működnek az importnál is, így nincs eltérés a kézi és az automatizált adatbevitel között.
Továbbfejlesztési irány: mesterséges intelligencia alapú hibakezelés
A jövőbeni fejlesztéseink egyik iránya, hogy az importfolyamat hibakezelését részben mesterséges intelligencia – pontosabban nagy nyelvi modellek (LLM-ek) – támogassa. Ennek célja, hogy a rendszer ne csak azonosítsa a hibákat, hanem javaslatokat is tegyen azok javítására, sőt bizonyos esetekben automatikusan képes legyen a korrekcióra. Ez nemcsak gyorsítja az adatfeldolgozást, hanem jelentősen csökkenti az ügyféltámogatási igényt is.
Szeretnél hasonlóan robusztus, validáció-alapú importfolyamatot a saját rendszeredhez is? Segítünk kialakítani a stratégiát – legyen szó technikai tervezésről vagy fejlesztésről.
Oszd meg ismerőseiddel!